presentations
Random presentations (both in Spanish and English)
This project is maintained by jgbarah
Generative AI models running in your own infrastructure
AI: Activities for all ages and subjects
Madrid, Spain, May 11, 2026
Jesus M. Gonzalez-Barahona
https://jgbarah.github.io/presentations/
What’s in a generative model
- Architecture
- Weights, just weights
- Software to make inferences
But also:
- Data to train, benchmark
- Software to train, benchmark
- Weights of intermediate models
- Documentation, explaining everything
A wide spectrum
- Behind-app model
- Directly accessible model
- Available weights model
- Open weight model
- Open source model
- Reproducible (libre) model
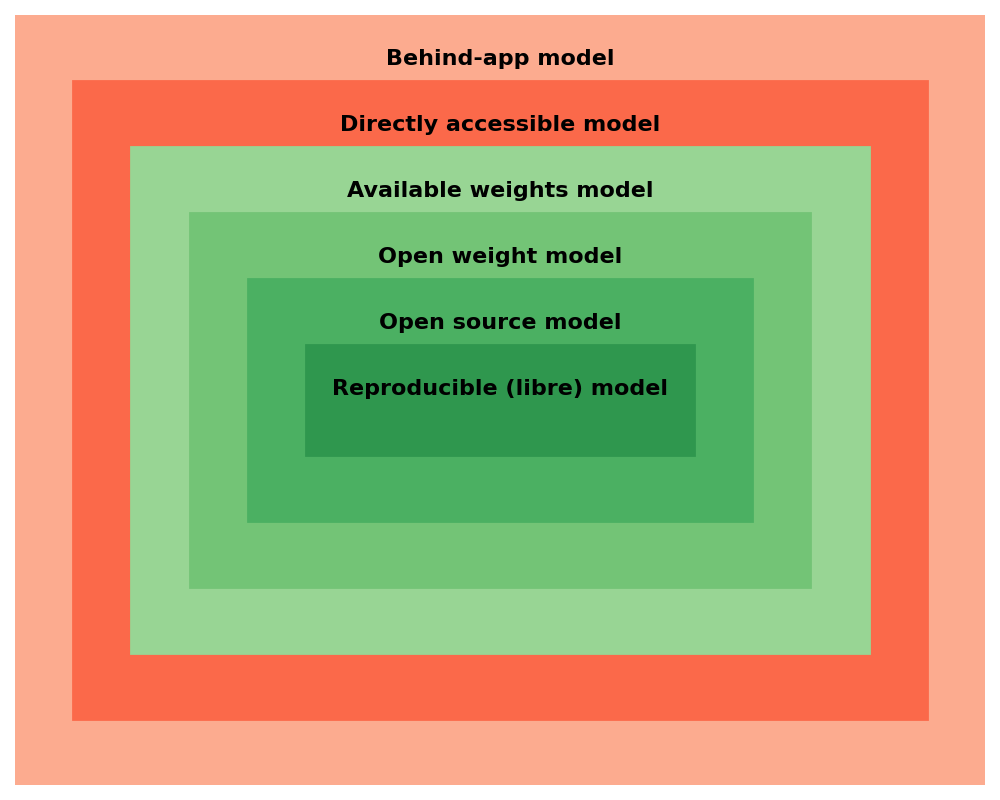
Classes of “openess”

https://arxiv.org/abs/2403.13784
Classes of “openess”
-
Open model: architecture, model parameters, weights & metadata, tech report, model card, data card
-
Open tooling: open model plus training, inference, and evaluation code, libraries, evaluation data
-
Open science: open tooling plus paper, datasets, log files, intermediate models parameters, weights & metadata
For each of them…
- Freedom of use
- Freedom of study
- Freedom of modification
- Freedom of sharing
The “four freedoms” from “What is Free Software?”
Some specific aspects
-
Access: can you run inferences the way you want?
-
Control on the model: can you modify the way the model works? (eg, finetune it)
-
Control on your data: can you control the prompt, the results?
-
Autonomy: how much you depend on the model provider?
-
Trust: can you ensure the model works as intended? (eg, backdoors, etc.)
Why this matters?
-
Model access: Use cases, innovation, integration
-
Model control: Use cases, innovation, integration
-
Data control: Privacy, ndependence, reliance
-
Autonomy: Market competition, independence, reliance
-
Trust: Security, transparency.
Behind-app model
-
An application uses one or more models to provide some service
-
It can be a local or cloud application
-
The application may be generalist or very specific
-
The model may change over time
- Google NotebookLM
- DeepL
- Windsurf in Visual Studio code
- HuggingFace Spaces
Behind-app model
-
Access: use the model only in the intended way
-
Model control: none
-
Data control: none
-
Autonomy: none
-
Trust: none
Directly accessible model
-
Access usually via HTTP API
-
The API defines to which extent the model can be controlled
-
Libraries and SDKs may be available
-
Designed for building apps, depending on the API
-
The model may change over time
- OpenRouter
- Groq
Directly accessible model
-
Access: use as you want, but API restricts parameters
-
Model control: limited, depending on the API
-
Data control: none
-
Autonomy: none
-
Trust: none
Available weights model
-
Weights are available
-
Usually, software for inferences is available / FOSS
-
Can be run on trusted infrastructure
-
Finetuning, etc. is usually possible
-
Redistribution, modification, use may be conditioned or forbidden
In some cases, referred as “open weight models”
Available weights model
-
Access: use as you want if conditions are met
-
Model control: deep control, if conditions are met
-
Data control: complete
-
Autonomy: depends on the conditions
-
Trust: none
Available weights models examples
- Kimi K2
- Modified MIT License
-
LLaMa3 models (2025-04)
- Meta Community License
- Meta’s LLaMa license is still not Open Source
Available weights models examples
- Gema3
- Gemma Terms of Use
- Mistral Small 4 (2026-03)
- Apache 2.0
Available weights models examples
- Tülu3
- Llama Community License
- Finetuned from Llama3.1
- All details and data of the finetune available
- Cohere Command A (2025-08)
- Creative Commons Attribution-NonCommercial 4.0 International and Cohere Terms of Use
Open weight model
-
Allows use, redistribution, derived works
-
No conditions for use
-
Derived works: finetuning, integration…
-
Does not require information about the model, its training, etc. (no freedom of study)
Open-Weight AI Models: What They Are, and Why OpenAI’s Next Move Matters
Open weight model
-
Access: use as you want
-
Model control: deep control
-
Data control: complete
-
Autonomy: only study is restricted
-
Trust: none
Open weight model example
- Granite Code (2024-11)
- Apache 2.0 License
- Very few information about the model, training, etc.
Open source model
-
Allows use, redistribution, derived works
-
No conditions for use
-
Derived works: finetuning, integration…
-
Open source software for training, inferencing
-
Detailed description of training, doesn’t require availability of the training dataset
Proposal – Interpretation of DFSG on Artificial Intelligence (AI) Models
Open source model
-
Access: use as you want
-
Model control: deep control
-
Data control: complete
-
Autonomy: detailed study is restricted
-
Trust: partial
Open source model examples
- DeepSeek (2025-09)
- MIT License
- GPT-OSS (2025-08)
- Apache 2.0 License
- Qwen3.5 (2026-02)
- Apache 2.0 License
Reproducible (libre) model
-
Allows use, redistribution, derived works
-
No conditions for use
-
Derived works: finetuning, integration…
-
All information about the model
-
Requires availability of the training dataset
Reproducible (libre) model
-
Access: use as you want
-
Model control: deep control
-
Data control: complete
-
Autonomy: complete
-
Trust: complete
Reproducible (libre) model examples
- Olmo3, technical report (2025-12)
- Apache 2.0 License
- MAP-Neo (2025-04)
- Apache 2.0 License
Reproducible (libre) model examples
- LLM360 K2, technical report (2024-07)
- Apertus (2025-09)
- Apache 2.0 License
- Alia (2026-02)
- Apache 2.0 License
| Access | Model Control | Data Control | Autonomy | Trust | |
|---|---|---|---|---|---|
| Behind-app | App-defined | None | None | None | None |
| Directly accessible | API restrictions | API restrictions | None | None | None |
| Available weights | With conditions | With conditions | Complete | With conditions | None |
| Open weight | Use as you want | Deep control | Complete | Study restricted | None |
| Open source | Use as you want | Deep control | Complete | Detailed study restricted | Partial |
| Reproducible | Use as you want | Deep control | Complete | Complete | Complete |
Reproducibility in AI research
Reproducible AI: Why it Matters & How to Improve it
Guidelines for Empirical Studies in Software Engineering involving Large Language Models
Ethical model
-
Conditions on use: “ethical use”
-
Conditions on training: “ethical datasets”
Depends on what is considered as “ethical”
Open issues
- Complex relationship of data, recipes, architecture, weights, software…
- Missing exact definitions for several of the categories
- It is not easy to find out in which category is a model
- Adapted definitions for finetunes and other evolutions of models?
- How to ensure that declarations are true?
Self-hostable models
Minimum for running in your infra
- Inference code, with libraries
- Model parameters & metadata (weights)
- Technical report (prompts, etc.)
- Model card (convenient)
At least, “available weights” if inference code is available
Self-hostable models
Self-hostable models
- If supporting software is available
- Available weights models
- Open weights models
- Open source models
- Reproducible models
Advantages of self-hostable
- Future availability is ensured
- You can run them in your infra
- You can integrate them easily
- Competition in the market for access via API
- You decide if running in cloud, or in the edge
Disadvantages of self-hostable
- Available models are usually not as good as the state of the art
- (maybe 6-12 months delay?)
- Improvement and support are not always happening
Advantages of self-hosting
- Full control of everything
- For many kinds of tasks, it is good enough
- Easier for reproducibility
Disadvantages of self-hosting
- Investment in infrastructure
- Limitations of the hardware you can get
- Maintenance is your responsibility
- Being up-to-date maybe a pain
- Decissions on best models
- Decisions on best software
- Decisions on best hardware
Technical skills required!
Equipment requirements
- Depends on architecture, and size of the model
- CPU can be enough, GPU can accelerate a lot
- Cloud options for GPUs
- RAM enough so that model fits
- Code is usually FOSS
You can also deploy in a cloud-based host
Economic aspects
- Hardware requirements
- Payback period
- Size and characteristics of the workload
- Sources of complexity:
- Multiple users, multiple models, etc
- Maintenance costs
- Energy consumption
You have to do the math
Locally runnable via API
- Many different providers, similar APIs
- Most of them use OpenAI API
- Many of them provide several models
- Examples: OpenRouter, Groq
- Frameworks provide backends for several providers
- Examples: LiteLLM, LangChain
- Easy testing of several models
- Depending on workload, can be cheaper
Quantization
- Used to reduce hw requirements
- From float32 to fp16, to int8, or less
- Usually, post-training
- Several formats:
- GPTQ, usually using
safetensorsfiles - GGUF, popular in the llama.cpp ecosystem
- GPTQ, usually using
HuggingFace Guide on Quantization
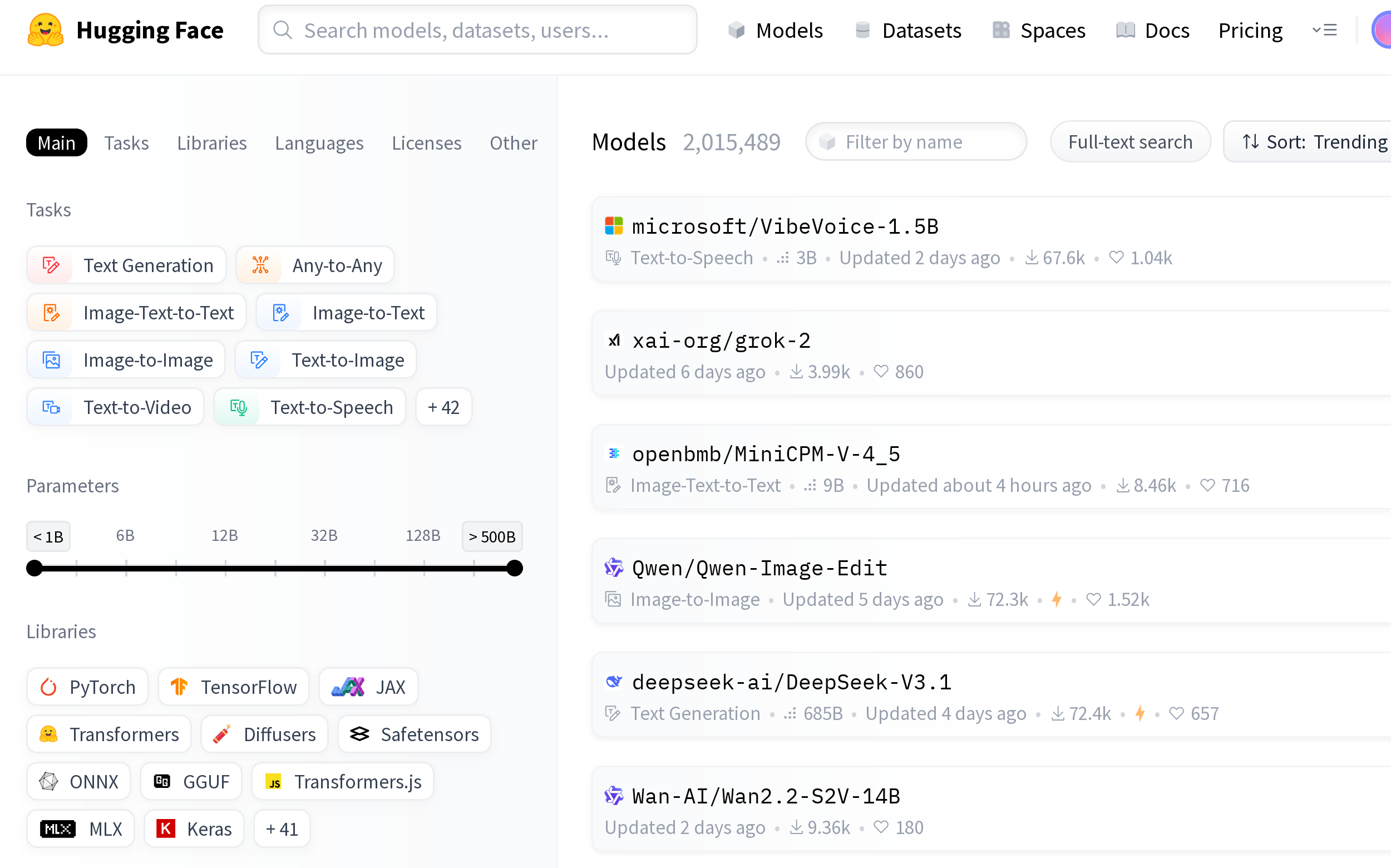
Finetuning
-
Adapting a model to a specific task with a (usually smaller) specialized dataset
-
Starting point: weights of given model.
-
Adjust weights to fit the specialized dataset
-
Adapter: new layers of weights added to a model to finetune it
HuggingFace: Quantizations and finetunes
Civit.AI: Images & videos
- Finetuning
- Quantizations
- Images and videos
https://civitai.com/
Inference engines
Frameworks for LLMs
-
LangChain: Chain together large LLM operations into sophisticated workflows, usually to build agent tools
-
LiteLLM: Agile toolset designed for efficiency and simplicity.
Both can use local models, of models via HTTP API
Chat / assistant frontends
-
Ollama, based on llama.cpp
-
Open WebUI: “almost” FOSS
-
Jan: Local assistant
Most of them also provide an HTTP API
Ollama: how to run
curl -fsSL https://ollama.com/install.sh | sh
ollama serve
ollama run gemma3:1b
curl http://localhost:11434/api/generate -d '{
"model": "gemma3:1b",
"prompt":"Why is the sky blue?"
}'
Using Ollama to host an LLM on CPU-only equipment to enable a local chatbot and LLM API
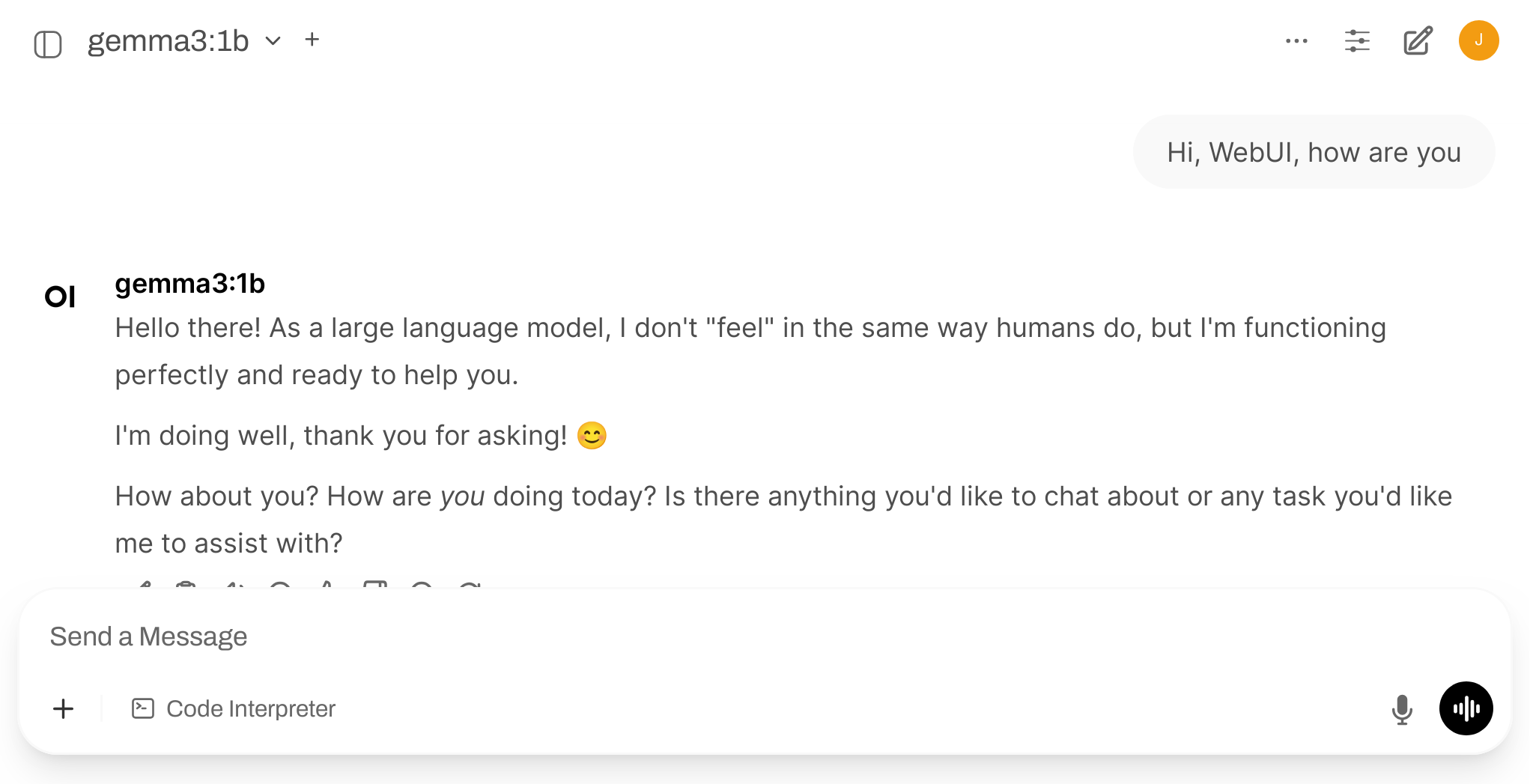
Open WebUI: how to run
uv venv --python 3.11
uv pip install open-webui
uv run open-webui serve
Now, open http://localhost:8080
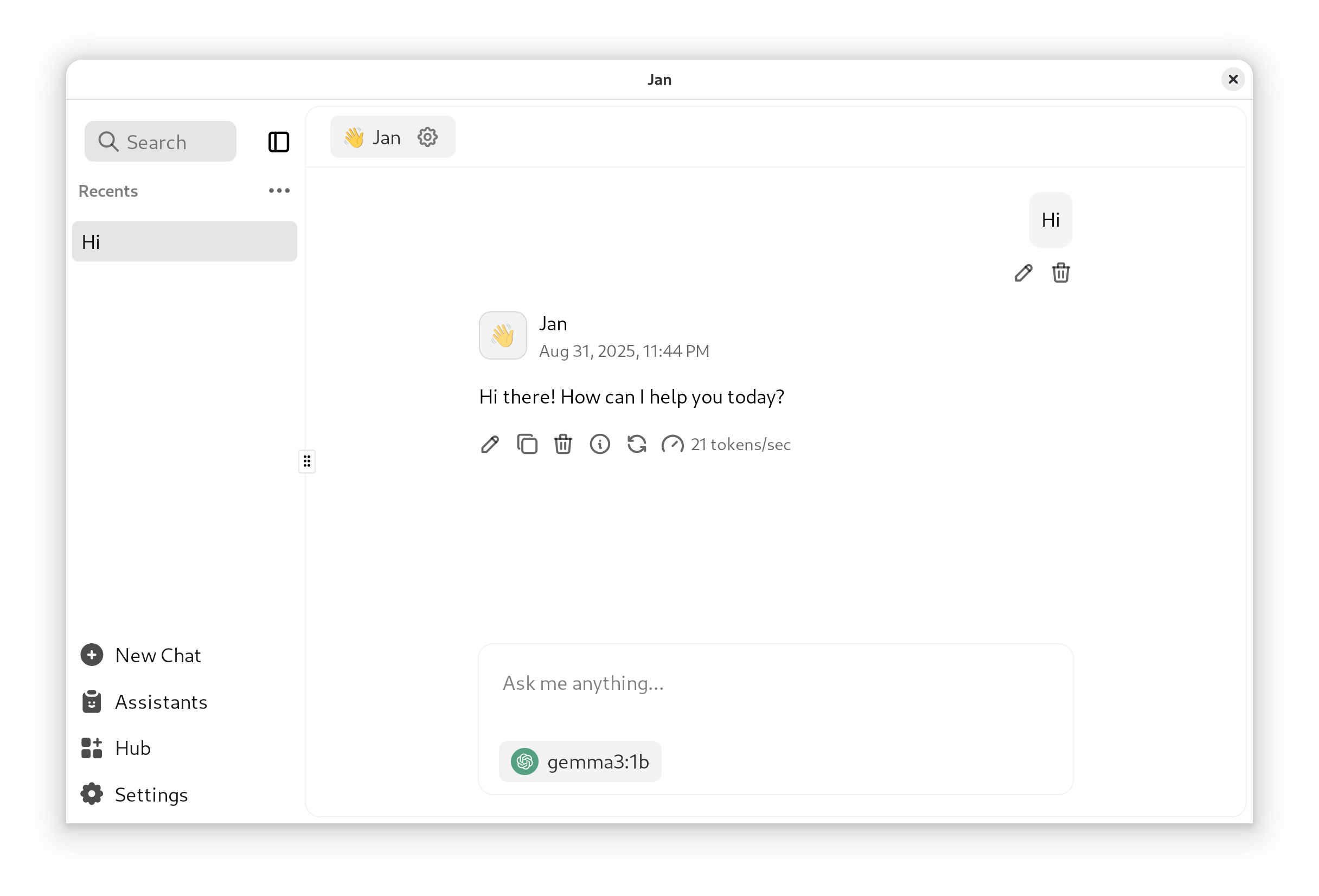
Jan: how to run
- Fetch the Debian package (or the one for your OS)
sudo pkg -i Jan_0.6.9_amd64.deb
Jan
- Settings > Model Providers >OpenAI
- API Key “ollama”
- Base URL: http://localhost:11434/v1
- Models: add a new one (“+”), “gemma3:1b”
- Select the model in the Chat
Other self-hostable generative models
Producing images
-
Qwen-Image, Apache 2.0 (2025-08)
-
HiDream-I1, MIT License (2025-07)
-
FLUX.1Kontext[dev], models, Flux Non-Commercial License (2025-08)
-
Stable Diffusion, models, StabilityAI Community License (2025-01)
A Guide to Open-Source Image Generation Models
Producing video
- Wan 2.2, repo, Apache 2.0 (2025-08)
- Hunyuan Video, repo, Tencent Hunyuan Community License
- LTX Video, repo, Apache 2.0
- Stable Video Diffusion, proprietary license, gratis for some uses
Text to video and image (apps & finetunes)
-
ComfyUI, repo: front-end and UI for several self-hostable text-to-image and text-to-video models
-
Wan2GP: front-ed and UI for several self-hostable text-to-video models
-
CivitAI: models and finetunes
Speech to text
Whisper, MIT License
uv venv
uv pip install openai-whisper
uv run whisper speech.wav --language Spanish
#!/usr/bin/python3
import whisper
model = whisper.load_model('tiny')
transcription = model.transcribe('recording.wav')
print(transcription['text'])
Text to speech
$ tts --text "Texto" \
--model_name tts_models/es/mai/tacotron2-DDC \
--out_path speech.wav
-
Kokoro, Apache 2.0 (2025-01)
-
Higgs Audio V2, Boson Higgs Audio 2 Community License (2025-07)
Text to speech (2)
-
Chatterbox, MIT License (2025-04)
-
MeloTTS & OpenVoice v2 MIT License (2024-02, 2024-04)
-
FishSpeech, CC Attribution-NonCommercial-ShareAlike (2025-08) (2024-11)
Exploring the World of Open-Source Text-to-Speech Models
Other random models
-
Understanding and reasoning about time series: ChatTS Apache 2.0, includes training dataset (2025-08)
-
360 immersive and explorable 3D worlds: HunyuanWorld
-
Text to 3D: LlamaMesh, Llama Community License (2024-11)
-
Open model and tools for building videos with AI: OpenSora
Other applications
- OpenCode: assistant, agentic
- CLI, web and desktop app
-
Hive: orchestrator for coding agents
-
AnythingLLM: assistant, agentic
-
FastSDCPU: image generation optimized for CPU
- Lemonade: LLM, image and speech generation tool
- Works well with Vulkan, apparently recognizing my Intel Iris GPU
Other applications (2)
-
OpenClaw: Agentic system
-
Hermes agent: Agentic system
-
Autoresearch: Self-improvign agent
-
Good night, have fun: Autoresearch-style agent, for coding
Other applications
-
SurfSense: comprehensive assistant
-
DeerFlow: comprehensive assistant
-
Hyprnote: note taking tool for meetings
-
TransformerLab: Train, Tune, Chat with LLMs
-
MobiRAG: chat with PDFs in your mobile
Open training datasets
- Chatbot Arena Leaderboard (How it works)
-
Common Corpus: The Largest Collection of Ethical Data for LLM Pre-Training
-
The Common Pile v0.1: An 8TB Dataset of Public Domain and Openly Licensed Text
- FineWeb, 18.5T tokens cleaned from CommonCrawl
Benchmarks
Bonus track
Some interesting tools
- HuggingChat
- Chat-like interface
- Many models, MCP servers…
- Petals
- Inference by distributed collaboration
Bonus track 2:
Are LLMs deterministic?
Why this matters?
-
Reproducible research: we want experiments that can be repeated by others, with the same results
-
Reproducible results: in some cases, it is important to be sure that a given input produces a given output. Always.
-
Reliable debugging: for debugging a problem, exact reproduction is often needed
-
Deterministic software: in some cases, we need software that is deterministic. Always.
Are LLMs deterministic?
-
Once weights are settled… the network itself doesn’t change
-
Determinism depends on:
- Inference engine
- System software
- Hardware
Inference engine
It is “regular”, deterministic software…
except when it tries to be random
Inference engine: controlling randomness (API parameters)
seedcan be fixed (initializes the pseudo-random number generator)temperature: 0 means “greedy sampling” (most probable next token)top_k(shortlist selector pool): 1 means the pool for selectable words is 1 (the most likely)top_p(nucleus sampling): chains of tokens to be considered. Difficult to control, interferes withtop_k
Inference engine: controlling randomness
-
Other parameters (eg, frequency or presence penalty) should be equal
-
Beware: the software may use random number generators in some other places
Inference engine: the balance
-
Randomness in inference is there for a reason: it can be useful for creativity, for getting better outputs
-
Two strategies:
- Keep randomness, but control it (controlling all seeds for randomness)
- Remove randomness, by controlling
temperature,top_k,top_p
Both can be combined
Supporting software
-
Mixtures of experts: prompt tokens routed differently depending on composition of batches from different users
-
Framework (PyTorch, TensorFlow): non-deterministic convolution algorithms (can be configured to be deterministic)
-
Differences in compilers, GPU drivers…
Hardware
- Floating point rounding: different rounding approaches in different hardware (happens even in int-quantified models)
- Non-deterministic hardware
References
-
Achieving Consistency and Reproducibility in Large Language Models (LLMs)
-
Solving Reproducibility Challenges in Deep Learning and LLMs: Our Journey
Beware!
- This is about reproducibility settings keeping setup:
- Keeping setup, and the same input, produce exactly the same output.
- Changing the hardware, GPU driver version, inference engine version, etc, may change results.
- This is not about predictable results:
- Slightly different inputs may lead to very different results, even with reproducible settings.
Summary
- Define a seed, this may be enough
temperature = 0top_k = 1- All other parameters should be equal
- Same inference software
- No mix of different inferences
- Same system software (GPU drivers, etc)
- Same hardware (CPU, GPU, etc)